


2018年11月16日更新
音声認識の今・昔・未来
今・昔・未来☆テクノロジー万華鏡は、「近未来の快適デジライフ」や「エンジニアリングなよもやまばなし」の掲載から10年経った今、果たして本当の「未来」はどうだったのか、そして、これからどうなって行くのかを考えるコンテンツです。
 以前から、家庭用のパソコンにも音声認識の機能が装備されているものがありました。しかし、認識の精度が低く、 使用される頻度は多くなかったと思います。現在ではほとんどのスマホにも音声認識の機能があり、話しかけるだけで答えを返してくれます。これからますます性能が良くなり、機械と世間話ができる時代が来るのでしょうか。
以前から、家庭用のパソコンにも音声認識の機能が装備されているものがありました。しかし、認識の精度が低く、 使用される頻度は多くなかったと思います。現在ではほとんどのスマホにも音声認識の機能があり、話しかけるだけで答えを返してくれます。これからますます性能が良くなり、機械と世間話ができる時代が来るのでしょうか。 
だからスマホとばっかりでなくて、たまにはわしや赤井くんやフクダ先輩ともお話ししてほしいのう(´・ω・`)
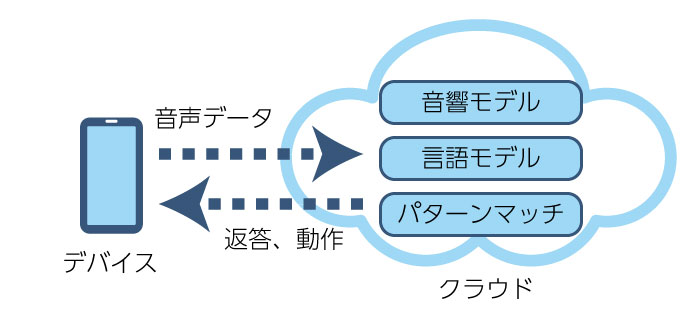
 現代ではスマホに標準装備されている音声認識。メールなどの文章を入力するのに利用できるだけでなく、話しかけるだけで必要な動作をしてくれたり、気の利いた回答をしたりします。話しかけるとスマホが答えてくれるように見えますが、実はクラウドにあるサーバーで音声の分析がされています。
現代ではスマホに標準装備されている音声認識。メールなどの文章を入力するのに利用できるだけでなく、話しかけるだけで必要な動作をしてくれたり、気の利いた回答をしたりします。話しかけるとスマホが答えてくれるように見えますが、実はクラウドにあるサーバーで音声の分析がされています。まず、音声データから音響モデルを使用して音素に分解します。そして言語モデルでその音素の組み合わせを言葉として分析します。その言葉をパターンマッチさせて答えを出力します。
 このパターンマッチによる会話技術は1966年に書き上げられたELIZA(イライザ)で既に実現されていたように古くからある技術ですが、現在では音声の分析、言語の分析、答えの出力それぞれに自動で学習するAIが組み込まれていて、精度が飛躍的に高まっているようです。
このパターンマッチによる会話技術は1966年に書き上げられたELIZA(イライザ)で既に実現されていたように古くからある技術ですが、現在では音声の分析、言語の分析、答えの出力それぞれに自動で学習するAIが組み込まれていて、精度が飛躍的に高まっているようです。また、最近ではクラウドへの接続を必要としない音声認識技術も登場してきました。
例えば、Snips社の音声プラットフォームではインターネット接続が不要で、デバイス上のみで稼働しながらAIによる高度な学習機能も持つため、インターネットへの接続が難しい照明器具やスピーカー、コーヒーメーカーなどの家電にも音声によるAIアシスタント機能を追加できます。
そして、使用者の音声データが機器内で処理されるため、コネクテッドホームでやりとりされる個人情報が保護されることも特長です。
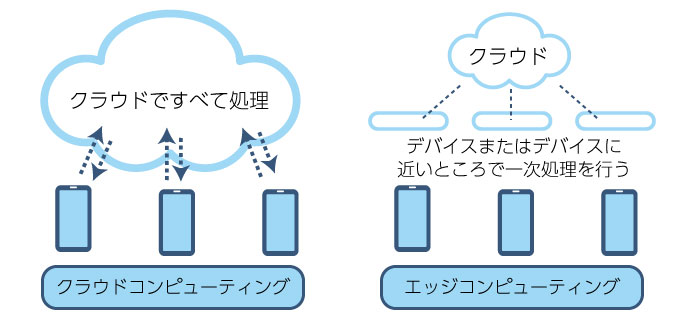
本格的なIoTの時代を迎え、クラウドの膨大なデータ処理の問題やセキュリティやプライバシー保護の問題を解決すると言われているエッジコンピューティングが音声認識にも活用されることで、「本当に単体で考えて答えるデバイス」の実現はまもなくかもしれません。

 スマホが考えて答えを話してくれる。未来が急に現実になったような気分になりますが、実はスマホが考えているのではなく、クラウド上のサーバーで音声が分析され、パターンマッチで会話のように回答しているのでした。しかし、AIによる自動学習の機能もますます向上し、クラウドコンピューティングからエッジコンピューティングへの移行も進んでいる状況から考えると、本当に手元のデバイスが自動学習して答えてくれるようになるのも遠い先では無さそうです。
スマホが考えて答えを話してくれる。未来が急に現実になったような気分になりますが、実はスマホが考えているのではなく、クラウド上のサーバーで音声が分析され、パターンマッチで会話のように回答しているのでした。しかし、AIによる自動学習の機能もますます向上し、クラウドコンピューティングからエッジコンピューティングへの移行も進んでいる状況から考えると、本当に手元のデバイスが自動学習して答えてくれるようになるのも遠い先では無さそうです。

